
Machine Learning verbessert die Erkennung eng platzierter Chipless RFID Tags
Eine neue IEEE-Studie zeigt, wie maschinelles Lernen dabei helfen kann, eng beieinanderliegende chiplose RFID-Tags zu identifizieren und zu lokalisieren, die mit herkömmlicher Signalverarbeitung nur schwer zu erkennen sind. Mithilfe von rastergescannten Rückstreumessungen und einem überwachten Klassifikator erstellt das Verfahren Wahrscheinlichkeitskarten, die sowohl den Tag-Typ als auch die Position anzeigen – selbst bei starker gegenseitiger Kopplung.
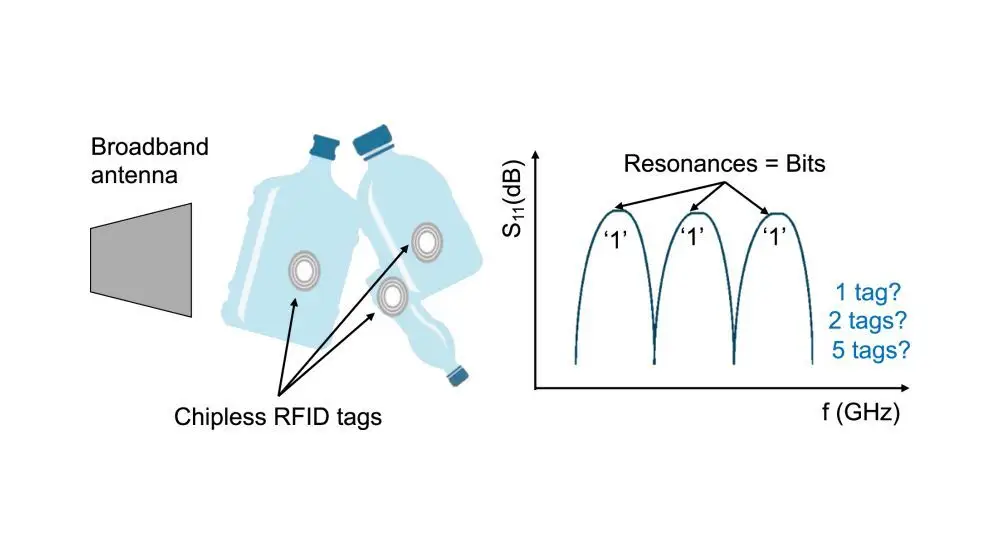
Eine anhaltende Herausforderung bei chiplosen RFID-Tags
Chiplose RFID ist attraktiv für extrem kostengünstige Tagging-Szenarien, in denen herkömmliche passive UHF-RFID zu teuer sein könnte. Die Technologie ist besonders relevant für Anwendungen mit hohem Volumen und geringen Margen, wie Materialidentifikation und Sortierung.
Eine wesentliche Einschränkung bleibt jedoch bestehen: Wenn sich mehrere chiplose Tags im Lesebereich befinden, überlagern sich ihre spektralen Antworten, was eine zuverlässige Identifizierung und Lokalisierung erschwert.
Im Gegensatz zu RFID mit Chip verwenden chiplose Systeme keine Antikollisionsprotokolle wie Slotted ALOHA. Stattdessen empfängt das Lesegerät eine kumulative Antwort von allen Tags in Sichtweite. Dies wird besonders problematisch, wenn Tags dicht beieinander platziert sind, da die gegenseitige Kopplung sowohl die spektralen als auch die räumlichen Signaturen verzerrt.
Maschinelles Lernen zur räumlich-spektralen Tag-Trennung
Die Studie schlägt einen auf maschinellem Lernen basierenden Rahmen zur Lösung dieses Problems vor. Der Ansatz nutzt einen 2D-Rasterscan mit einer gerichteten Lesegerätantenne, um die Stärke und Phase der Rückstreuungssignale in einem definierten Bereich zu erfassen. An jedem Scanpunkt wird das gemessene Signal von einem trainierten multinomialen logistischen Regressionsklassifikator verarbeitet.
Der Klassifikator schätzt die Wahrscheinlichkeit, dass ein bestimmter räumlicher Punkt zu einer von mehreren Klassen chiploser Tags gehört. Diese Ergebnisse werden dann in farbcodierte Wahrscheinlichkeitskarten umgewandelt, die zeigen, wo sich jedes Tag wahrscheinlich befindet und welcher Tag-Typ vorhanden ist.
Zur Extraktion der Tag-Identität und zur Schätzung der Tag-Positionen wird eine Nachbearbeitung auf Basis von Konturfilterung, Schwellenwertbildung und Clustering verwendet.
Versuchsaufbau mit drei Tag-Typen
Die Bewertung wurde mit drei Arten von Tags mit einzelnen kreisförmigen Resonatoren und unterschiedlichen Resonanzfrequenzen im Bereich von 2 bis 6 GHz durchgeführt. Bis zu zwei Tags wurden innerhalb eines 14 cm × 14 cm großen Messbereichs platziert und mit einer an einen Vektornetzwerkanalysator angeschlossenen Vivaldi-Antenne gescannt.
Das System erfasste 94 Rasterscan-Instanzen, die sowohl isolierte als auch eng beieinanderliegende Tag-Konfigurationen abdeckten. Es wurden Messungen sowohl für die Amplitude als auch für die Phase durchgeführt, was einen Vergleich zwischen den beiden Signalbereichen ermöglichte.
Ein zentrales Ziel der Arbeit war es, Tags bei Abständen unter 0,6λ aufzulösen – ein Bereich, in dem bisherige Methoden aufgrund von Kopplungseffekten Schwierigkeiten hatten. Dieser Schwellenwert ist relevant, da er sich der praktischen Auflösungsgrenze für passive Mikrowellenstrukturen annähert.
Hohe Genauigkeit bei phasenbasierten Messungen
Die berichteten Ergebnisse zeigen, dass die Methode bei der Verwendung von Phasendaten besonders gut funktioniert. Die Tag-Identifizierung erreichte eine Genauigkeit von 100 Prozent bei Phasenmessungen und 97,82 Prozent bei Amplitudendaten.
Auch die Lokalisierungsleistung verbesserte sich mit der Phase deutlich. Der durchschnittliche euklidische Lokalisierungsfehler betrug 6,4 mm bei der phasenbasierten Verarbeitung, verglichen mit 1,19 cm bei der amplitudenbasierten Verarbeitung. Den Autoren zufolge zeigt dies eine Genauigkeit im Subzentimeterbereich, selbst wenn Tags näher beieinander liegen als der bisher nicht auflösbare Abstand von 0,6λ.
Für Entwickler von chiplosen RFID-Systemen ist das Ergebnis relevant, da es zeigt, dass maschinelles Lernen durch Kopplung verursachte Verzerrungen kompensieren kann, die mit herkömmlichen analytischen Methoden allein nur schwer zu bewältigen sind.
Relevanz für skalierbare chiplose RFID-Anwendungen
Die vorgeschlagene Methode beseitigt ein zentrales Hindernis für einen breiteren Einsatz von chiplosen RFID-Systemen: das gleichzeitige Auslesen mehrerer nahe beieinander liegender Tags. Dies ist besonders wichtig in Anwendungen wie Recycling, Sortierung und kostengünstiger Bestandsidentifizierung, wo Durchsatz und eine hohe Tag-Dichte entscheidend sind.
Durch die Kombination von rastergescannten Rückstreudaten mit überwachtem Lernen eröffnet die Studie einen neuen Weg hin zum räumlich aufgelösten Multitag-Lesen in der chiplosen RFID. Für Systemintegratoren und Technologieentwickler legt die Arbeit nahe, dass eine KI-basierte Interpretation dazu beitragen könnte, die chiplose RFID über Szenarien mit einzelnen Tags oder weit voneinander entfernten Tags hinaus weiterzuentwickeln.
Aktuelle Grenzen und nächste Schritte
Die Autoren weisen darauf hin, dass der Ansatz derzeit unter kontrollierten Laborbedingungen demonstriert wird. Die Übertragung auf reale Einsatzszenarien bleibt aufgrund von Umgebungsempfindlichkeit, fehlenden standardisierten Messprotokollen und der begrenzten Verfügbarkeit großer chiploser RFID-Datensätze eine Herausforderung.
Zukünftige Arbeiten werden sich auf größere und vielfältigere Tag-Populationen, realistischere Umgebungen, die Generierung synthetischer Trainingsdaten und fortgeschrittenere Modelle des maschinellen Lernens wie U-Net-basierte Architekturen konzentrieren. Die Forscher verweisen zudem auf Phased-Array-Systeme als möglichen Weg hin zu Echtzeitbetrieb und großflächigem Scannen.
Ausblick
Die Studie zeigt, dass maschinelles Lernen sowohl die Identifizierung als auch die Lokalisierung von eng beieinander liegenden chiplosen RFID-Tags unter Bedingungen verbessern kann, unter denen herkömmliche Methoden versagen. Obwohl die Methode nach wie vor auf kontrolliertes Scannen und trainierte Modelle angewiesen ist, liefert sie einen praktischen Proof of Concept für die Bewältigung einer der hartnäckigsten technischen Einschränkungen bei chiplosen RFID-Systemen.
Lesen Sie den vollständigen Artikel hier: https://ieeexplore.ieee.org/document/11368724
Über die Autoren
Der Artikel wurde von Forschern des Auto-ID Labs am Massachusetts Institute of Technology (MIT) in Cambridge, USA, verfasst, einer Gruppe, die für ihre Arbeit an Identifikationstechnologien, Sensorsystemen und RFID-bezogener Forschung bekannt ist.
F. Villa-Gonzalez, H. Li, R. Bhattacharyya, Sobhi Alfayoumi und S. E. Sarma sind alle dem Auto-ID Labs am MIT angegliedert. Ihre Arbeit in dieser Studie konzentriert sich auf den Einsatz von maschinellem Lernen zur Verbesserung der Identifizierung und Lokalisierung von dicht beieinander liegenden chiplosen RFID-Tags und befasst sich damit mit einer seit langem bestehenden Herausforderung beim Design chiploser RFID-Systeme.