
L’IA améliore la détection des étiquettes RFID sans puce proches
Une nouvelle étude de l'IEEE montre comment l'apprentissage automatique peut aider à identifier et à localiser des étiquettes RFID sans puce très proches les unes des autres, difficiles à distinguer avec les techniques classiques de traitement du signal.
À l'aide de mesures de rétrodiffusion par balayage tramé et d'un classificateur supervisé, cette méthode permet de reconstruire des cartes de probabilité indiquant à la fois le type et la position des étiquettes, même en cas de fort couplage mutuel.
Un défi persistant dans le domaine de la RFID sans puce
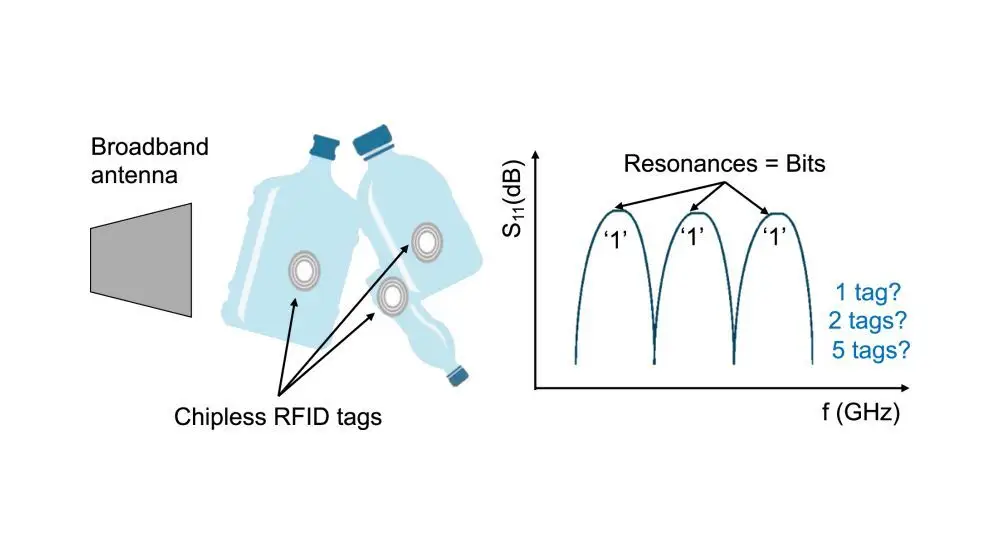
La RFID sans puce est intéressante pour les scénarios de marquage à très faible coût où la RFID UHF passive classique peut s'avérer trop onéreuse. Cette technologie est particulièrement adaptée aux applications à haut volume et à faible marge, telles que l'identification et le tri des matériaux. Cependant, une limitation majeure subsiste : lorsque plusieurs étiquettes sans puce sont présentes dans le champ du lecteur, leurs réponses spectrales se superposent, rendant difficile une identification et une localisation fiables.
Contrairement à la RFID à puce, les systèmes sans puce n'utilisent pas de protocoles anticollision tels que l'ALOHA à créneaux. Au lieu de cela, le lecteur reçoit une réponse cumulative de toutes les étiquettes dans son champ de vision. Cela devient particulièrement problématique lorsque les étiquettes sont placées à proximité les unes des autres, car le couplage mutuel déforme à la fois les signatures spectrales et spatiales.
L'apprentissage automatique appliqué à la séparation spatio-spectrale des étiquettes
L'étude propose un cadre basé sur l'apprentissage automatique pour résoudre ce problème. L'approche utilise un balayage raster 2D avec une antenne de lecture directive pour collecter les réponses de magnitude et de phase rétrodiffusées sur une zone définie. À chaque point de balayage, le signal mesuré est traité par un classificateur de régression logistique multinomiale entraîné.
Le classificateur estime la probabilité qu'un point spatial donné appartienne à l'une des différentes classes de balises sans puce. Ces résultats sont ensuite convertis en cartes de probabilité codées par couleur qui indiquent où chaque balise est susceptible de se trouver et quel type de balise est présent. Un post-traitement basé sur le filtrage des contours, le seuillage et le regroupement est utilisé pour extraire l'identité des balises et estimer leurs positions.
Configuration expérimentale avec trois types d'étiquettes
L'évaluation a été réalisée à l'aide de trois types d'étiquettes à résonateur annulaire unique présentant des fréquences de résonance distinctes comprises entre 2 et 6 GHz. Jusqu'à deux étiquettes ont été placées dans une zone de mesure de 14 cm × 14 cm et balayées à l'aide d'une antenne Vivaldi connectée à un analyseur de réseau vectoriel.
Le système a collecté 94 instances de balayage tramé, couvrant à la fois des configurations de balises isolées et très rapprochées. Des mesures ont été effectuées à la fois pour l'amplitude et la phase, permettant une comparaison entre les deux domaines de signal.
L'un des principaux objectifs de ces travaux était de résoudre des étiquettes à des espacements inférieurs à 0,6λ, une plage où les méthodes précédentes rencontraient des difficultés en raison des effets de couplage. Ce seuil est pertinent car il se rapproche de la limite de résolution pratique pour les structures micro-ondes passives.
Haute précision grâce aux mesures de phase
Les résultats présentés montrent que la méthode est particulièrement performante lorsqu'elle utilise des données de phase. L'identification des balises a atteint une précision de 100 % avec les mesures de phase et de 97,82 % avec les données d'amplitude.
Les performances de localisation se sont également considérablement améliorées grâce à la phase. L'erreur de localisation euclidienne moyenne était de 6,4 mm pour le traitement basé sur la phase, contre 1,19 cm pour le traitement basé sur l'amplitude. Selon les auteurs, cela démontre une précision inférieure au centimètre, même lorsque les étiquettes sont placées à une distance inférieure à l'espacement de 0,6λ, jusqu'alors non résolu.
Pour les développeurs de systèmes RFID sans puce, ce résultat est pertinent car il indique que l'apprentissage automatique peut compenser les distorsions induites par le couplage, difficiles à traiter avec les seules méthodes analytiques conventionnelles.
Pertinence pour les applications RFID sans puce évolutives
La méthode proposée s'attaque à un obstacle majeur au déploiement à plus grande échelle de la RFID sans puce : la lecture simultanée de plusieurs étiquettes proches. Cela est particulièrement important dans des applications telles que le recyclage, le tri et l'identification d'actifs à faible coût, où le débit et la densité des étiquettes sont déterminants.
En combinant des données de rétrodiffusion acquises par balayage tramé avec l'apprentissage supervisé, l'étude ouvre une nouvelle voie vers la lecture multi-étiquettes à résolution spatiale en RFID sans puce. Pour les intégrateurs de systèmes et les développeurs de technologies, ces travaux suggèrent que l'interprétation basée sur l'IA pourrait aider à faire évoluer la RFID sans puce au-delà des scénarios à étiquette unique ou à étiquettes largement espacées.
Limites actuelles et prochaines étapes
Les auteurs notent que l'approche est actuellement démontrée dans des conditions de laboratoire contrôlées. La généralisation à des déploiements en conditions réelles reste difficile en raison de la sensibilité environnementale, de l'absence de protocoles de mesure standardisés et de la disponibilité limitée de grands ensembles de données RFID sans puce.
Les travaux futurs se concentreront sur des populations de balises plus importantes et plus diversifiées, des environnements plus réalistes, la génération de données d'entraînement synthétiques et des modèles d'apprentissage automatique plus avancés, tels que les architectures basées sur U-Net. Les chercheurs évoquent également les systèmes à réseau phasé comme une voie possible vers un fonctionnement en temps réel et un balayage de zones plus étendues.
Perspectives
Cette étude montre que l'apprentissage automatique peut améliorer à la fois l'identification et la localisation de balises RFID sans puce très rapprochées dans des conditions où les méthodes conventionnelles échouent. Bien que cette méthode repose encore sur un balayage contrôlé et des modèles entraînés, elle fournit une preuve de concept pratique pour surmonter l'une des limitations techniques les plus persistantes de la RFID sans puce.
Lire l'article complet ici : https://ieeexplore.ieee.org/document/11368724
À propos des auteurs
Cet article a été rédigé par des chercheurs de l'Auto-ID Labs du Massachusetts Institute of Technology (MIT), à Cambridge, aux États-Unis, un groupe connu pour ses travaux sur les technologies d'identification, les systèmes de détection et la recherche liée à la RFID.
F. Villa-Gonzalez, H. Li, R. Bhattacharyya, Sobhi Alfayoumi et S. E. Sarma sont tous affiliés à l'Auto-ID Labs du MIT. Dans cette étude, leurs travaux se concentrent sur l'utilisation de l'apprentissage automatique pour améliorer l'identification et la localisation de balises RFID sans puce très rapprochées, relevant ainsi un défi de longue date dans la conception des systèmes RFID sans puce.